Speech Style Editing (SSE) aims to modify selected style attributes (e.g., timbre, emotion, pitch) while preserving the linguistic content and all other style attributes that are not given.
Many speech applications require flexible control over speech style, making SSE increasingly important.
Existing SSE approaches typically follow a style-generation paradigm that synthesizes non-linguistic attributes from style conditions.
However, this often results in limited preservation of source attributes and insufficient flexibility when only a subset of style attributes is specified.
To overcome these limitations, we adopt a style editing paradigm, in which the target style is achieved by adjusting the source speech instead of producing speech from scratch.
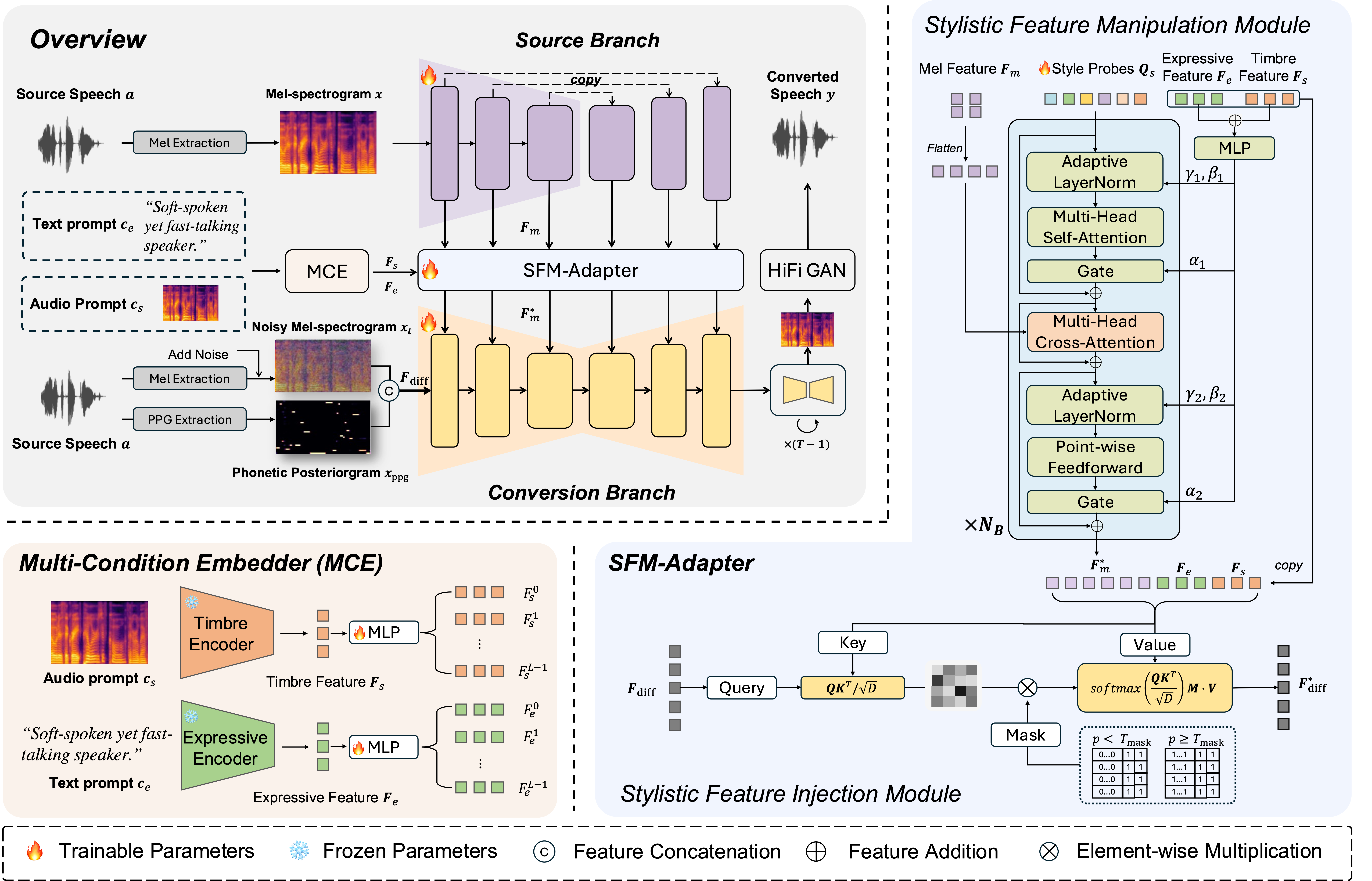
Building on this paradigm, we propose a diffusion-based framework with a Style-aware Feature Manipulation Adapter (SFM-Adapter).
The SFM-Adapter performs feature-level modulation by integrating user-provided style information with source speech features through multi-layer cross-attention. The resulting modulated features are incorporated into the generation process via mask attention.
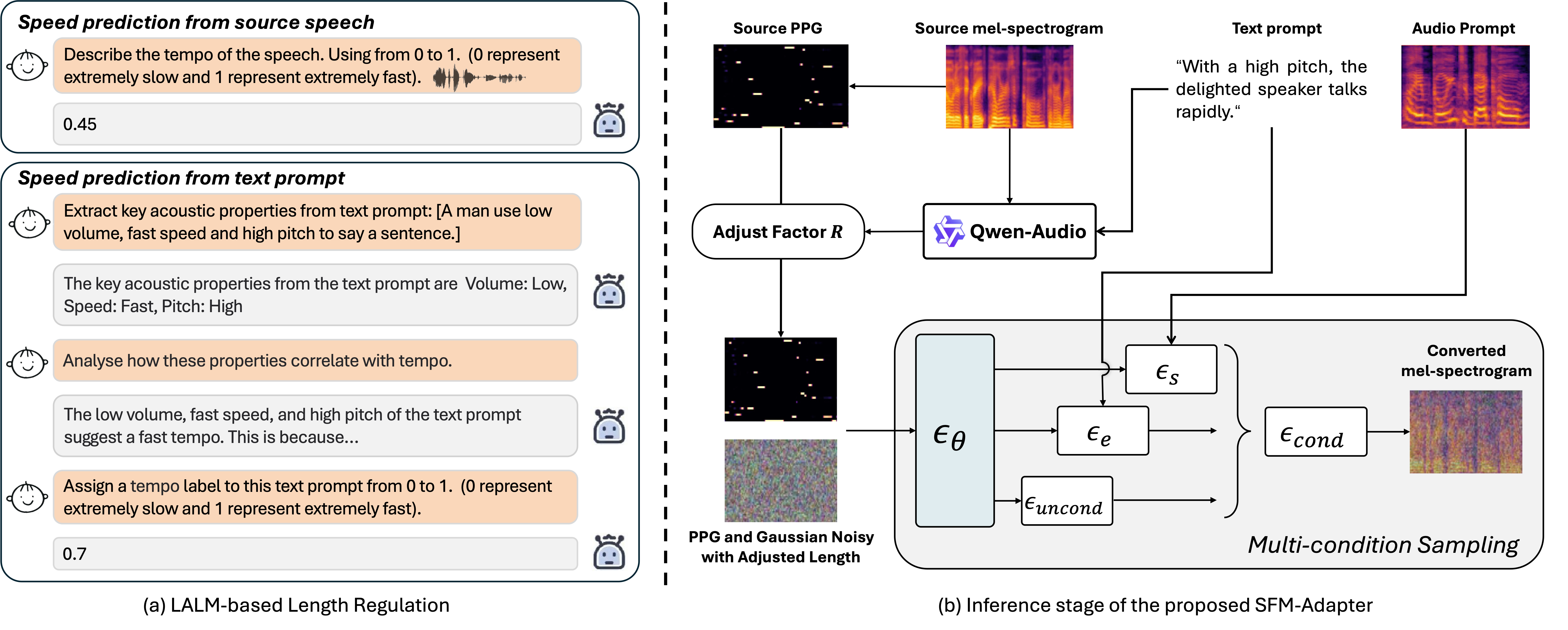
During inference, a Large Audio-Language Model (LALM)-based length regulation is designed to predict speaking speed and adjust duration.
Experiments across multiple speech style editing tasks demonstrate that the SFM-Adapter achieves more natural, accurate, and source-preserving style editing compared with existing methods.